| Japanese | English |
| Date: | 17:00, 25 Sep. 2002 |
| Place: | Nagoya, Japan |
| Microphone: | SONY ECM-MS957 |
| Microphone amplifier | SONY DAT WALKMAN TCD-D100 |
| Personal computer: | DELL INSPIRON 7500 |
| OS: | Windows 2000 Professional |
| Software: | DSSF3 |
| WAVE sound file: |
Note: In this measurement and later, microphone amplifier is used to improve the S/N ratio. The running ACF measurement is performed with monitoring the result in RA.
The power spectrum of female voice /a/. The graph is zoomed up into 100-5k
Hz. The "level range" and the "frequency range" were
adjusted manually.
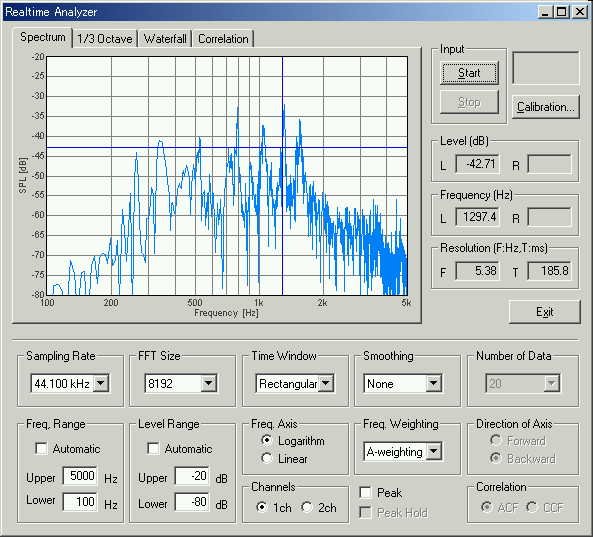
The fundamental frequency is found at 260 Hz. Formant frequency is seen at 800 Hz and higher harmonics are found at 1060, 1500, 1750.
As a reference, it is said that the fundamental frequency of general female voice is 225 Hz. Male voice has 120 Hz and a small child's voice has 300 Hz (Ray D. Kent and Charles Read, "The acoustic analysis of speech", 1992, Singular Publishing Group, Inc. ).
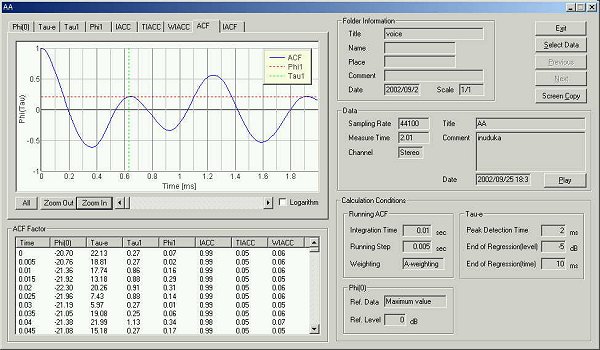
Next, the running ACF was checked to find the peak at this formant frequency (800 Hz).
The maximum peak in the ACF is found at 1.25 ms. This corresponds to 800 Hz
(1000/1.25).
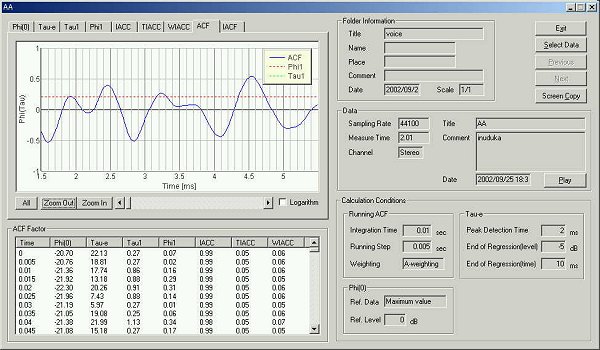
In the same graph, the peak at 4.55 ms is found. This peak is the fundamental
frequency at 219 Hz.
The peak identified is not fixed during utterance. It is necessary to gather the data not only for an instant but its time change. Next, as in the last time, the ACF is calculated in every 5ms after the utterance.
This is the running ACF analysis window.
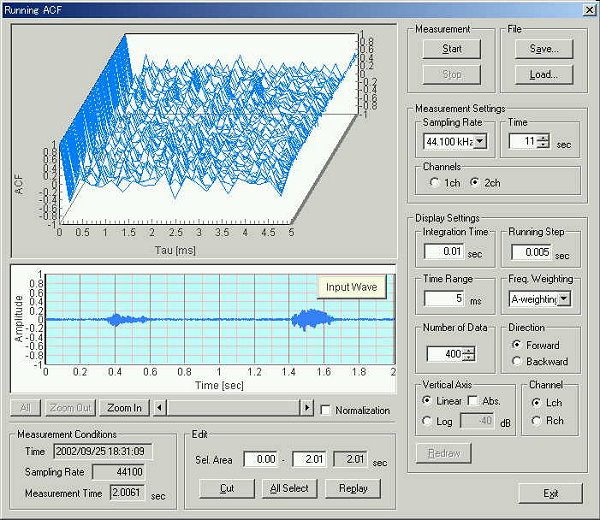
5 ms after the utterance.
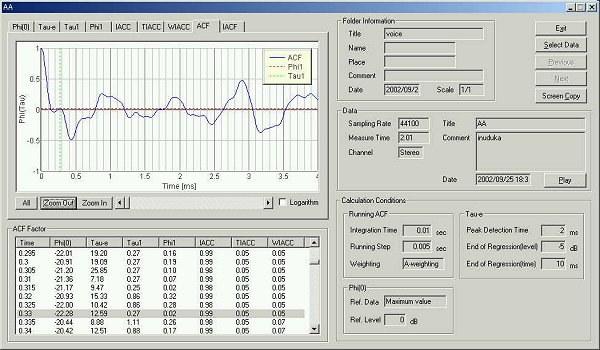
The te value is 12.58 ms. From the beginning of utterance to the maximum power level, the te decreases roughly. In the ACF waveform, there are several peaks at 0.2, 0.28, 0.4, 0.68, 0.85, 1,1.18, 1.2, 1.35, 1.7, 1.95 ms.
10 ms after the utterance
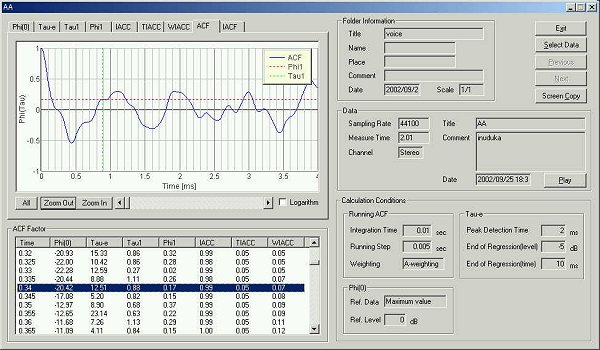
The te value is 12.51 ms.
In the figure above, there are several peaks at 0.2, 0.4, 0.6, 0.9, 1.1 ms. Also you can see a large peak at 3.8 ms. This seems the fundamental frequency. This time, the fundamental frequency was identified until 10 ms.
Formant frequency
15 ms after the utterance
The te value is 5.20 ms.
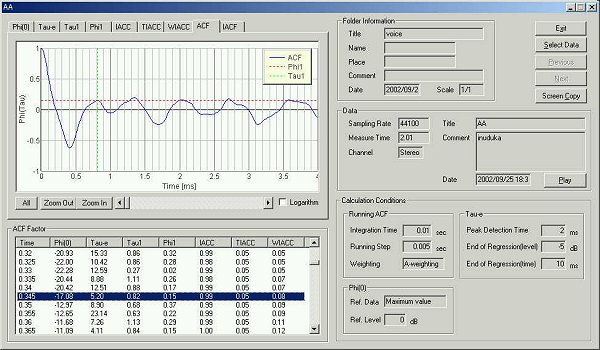
The lowest peak in the spectrum is called the first formant (F1), followed by the other formants F2, F3, and so on. As for the autocorrelation for 15ms after utterance, each above-mentioned peak corresponds to the formant frequencies.
20 ms after the utterance
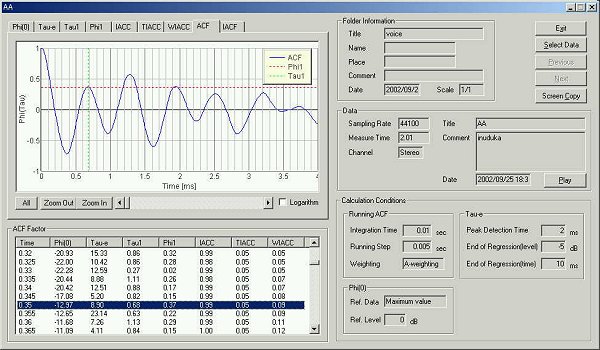
25 ms after the utterance
Here, these values are compared with those of male voice.
Male voice has slightly lower formant frequencies. Also, male voice has the wide bandwidth at low frequency as shown in the spectrum. The highest frequency of the male voice is 3 kHz. That is different from the female voice that has higher frequency until 12 kHz.
So, the ACF of the female voice has clear peaks in the short range. These peaks represent formant frequencies separately. Doesn't this mean that female voice tends to be intelligible rather than male voice?
April 2003 by Masatsugu Sakurai